En los años sesenta, las redes y los sistemas jerárquicos como CODASYL e IMSTM fueron el estado del arte de la tecnología para automatizar la banca, contabilidad, y el procesamiento de órdenes debido a la introducción de computadoras Mainframe. Mientras estos sistemas proveían una buena base para los primeros sistemas, su arquitectura básica mezcló la […]
Por Federico Wiesse. 16 febrero, 2012.En los años sesenta, las redes y los sistemas jerárquicos como CODASYL e IMSTM fueron el estado del arte de la tecnología para automatizar la banca, contabilidad, y el procesamiento de órdenes debido a la introducción de computadoras Mainframe. Mientras estos sistemas proveían una buena base para los primeros sistemas, su arquitectura básica mezcló la manipulación física de datos con su manipulación lógica. Cuando la ubicación física de datos cambia, como de un área de un disco a otro, las aplicaciones tuvieron que ser actualizadas en lo referente a la nueva ubicación.
Un artículo revolucionario de E.F. Codd, un empleado de los Laboratorios de Investigación de San José – IBM en 1970, cambió todo esto. El artículo titulado “Un modelo relacional de datos para almacena grandes datos compartidos” introdujo la noción de independencia de los datos que separó la representación física de datos de la representación lógica presente en las aplicaciones. Podrían moverse los datos de una parte del disco a otro o podrían guardarse en un formato diferente sin causar que se vuelvan a escribir las aplicaciones. Los diseñadores de la aplicación se libraron de los tediosos detalles físicos de manipulación de los datos, y en cambio pudieron enfocarse en la manipulación lógica de datos en el contexto de su específica aplicación.
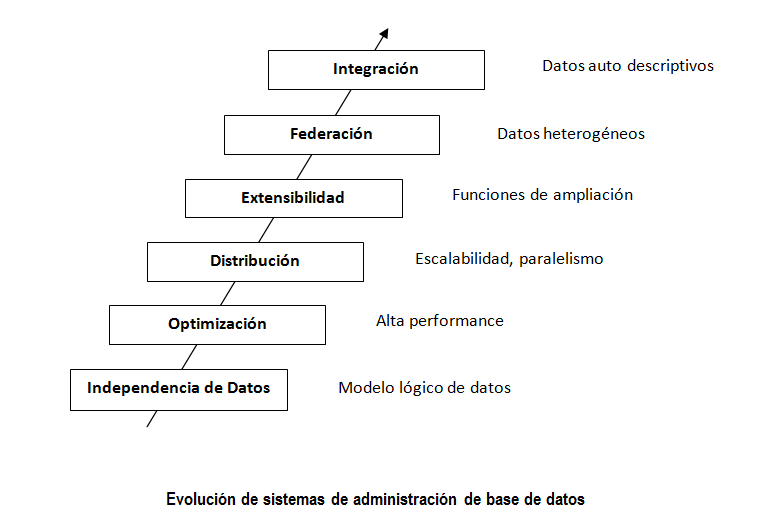
La figura describe la evolución del sistema de administración de base de datos con el modelo relacional que conserva la independencia de los datos. El Sistema R de IBM fue el primer sistema que implemento las ideas de Codd. El sistema R fue la base para SQL/DS que después fue DB2. También tiene el mérito de introducir SQL, un idioma de base de datos relacional usado como una norma hoy, y abrió la puerta para los sistemas de administración de base de datos comerciales.
Hoy, los sistemas de administración de base de datos relacionales son el la mayoría DBMS y son desarrollados por varias compañías del software. Los DBMS relacionales son Oracle, Microsoft SQL Server, DB2, INGRES, PostgreSQL, MySQL y dBASE.
Cuando las bases de datos relacionales se hicieron populares, ha surgido la necesidad de ofrecer consultas de alta performance. El optimizador de consultas es uno de los componentes más sofisticados de los DBMS. Desde la perspectiva de un usuario, se trata al optimizador como una caja negra, y pasa cualquier consulta SQL a él. El optimizador calcula la manera más rápida de recuperar sus datos teniendo en cuenta muchos factores como la velocidad de su CPU y discos, la cantidad de datos disponible, la situación de los datos, el tipo de datos, la existencia de índices, y así sucesivamente.
Como aumentó la cantidad de datos reunidos y guardados en una base de datos, DBMS han escalado. Hay DBMS para Linux, UNIX y Windows, por ejemplo, un rasgo llamado Función de Partición de Base de datos (DPF) permite extender una base de datos por muchas máquinas que usan una arquitectura no-compartida. Cada máquina agregada trae sus propios CPUs y discos; por consiguiente, es más fácil escalar casi linealmente. Una consulta en este entorno realiza la recuperación en paralelo y cada máquina recupera una porción del resultado global.
DBMS evolucionó, luego, con el concepto de extensibilidad. El Lenguaje de la Consulta Estructurada (SQL) inventado por IBM en los inicios de 1970 a través de los años ha sido constantemente mejorado. Aunque es un idioma muy poderoso, los usuarios también están autorizados a desarrollar su propio código que permita extender el SQL. Por ejemplo, usted puede crear funciones definidas por el usuario, y guardar procedimientos que le permiten extender el lenguaje SQL con su propia lógica.
Entonces los DBMS empezaron a ocuparse del problema de diferentes tipos de datos y de diversas procedencias. Actualmente los servidores de batos pueden guardar todos los tipos de información que incluyen video, audio, datos binarios y así sucesivamente. Es más, a través del concepto de estandarización una consulta podría usarse un DBMS como DB2 para acceder a los datos de otros productos de IBM, y de productos que no sean de IBM.
Por último, en la figura 1 el próximo paso evolutivo resalta la integración. Hoy muchos negocios necesitan intercambiar la información, y el Lenguaje de Etiquetado extensible (XML) es la tecnología subyacente que se usa para este propósito. XML es extensible, describiéndose a sí mismo como lenguaje. Su uso ha estado creciendo exponencialmente debido a Web 2.0, y a la arquitectura orientada a servicios (SOA).
En la actualidad el tema que está vigente es el “Cloud Computing”. Hay ya de hecho, imágenes de DBMS disponible en la Nube Amazon EC2, y en el Desarrollo de Negocios Inteligentes y Prueba en la Nube de IBM (también conocido como el Desarrollo y prueba de IBM en la Nube). La partición de Base de datos descrito anteriormente encaja perfectamente en la nube donde puede solicitar un nodo estándar o un servidor a demanda, y agregar entonces esto a tu nube. El reequilibrio de los datos es realizado automáticamente por el DBMS. Esto puede ser muy útil en el momento cuando más poder necesita ser dado al servidor de la base de datos para ocuparse de las transacciones de fin de mes o transacciones de fin de año.







