El doctor César Angulo, docente de la Facultad de Ingeniería, explica los aspectos básicos que se deben tener en cuenta para interpretar y diseñar una encuesta de opinión confiable.
Por César Angulo. 03 diciembre, 2018.Las encuestas de opinión se hacen para estimar qué porcentajes de una población opinan de una u otra manera. Si se pretendiera conocer con exactitud dichos porcentajes, se tendría que preguntar la opinión a todos; es decir, hacer un censo. Como esto no es posible, pues se requeriría de mucho tiempo y dinero, se recurre al muestreo: con una muestra representativa de la población, de tamaño adecuado y seleccionada de forma aleatoria.
La forma más práctica de conseguir una muestra aleatoria es dividir la población en estratos: socioeconómicos, sexos, regiones o distritos, rangos de edades, etc., y luego obtener submuestras de dichos estratos, proporcionales al tamaño de cada uno.

Por ejemplo, la provincia de Piura está dividida en diez distritos, y cada uno de ellos contiene los siguientes porcentajes de electores: Piura (27%), Castilla (19%), Catacaos (10%), La Unión (5%), Las Lomas (4%), Tambogrande (13%), etc. Entonces, una muestra de 1000 electores debería contener a 270 de Piura, 190 de Castilla, 100 de Catacaos, 50 de La Unión, 40 de Las Lomas, 130 de Tambogrande, etc. Para obtener las submuestras en cada distrito existen técnicas que garantizan la aleatoriedad. Este procedimiento asegura que sea lo más representativa posible de la población.
La confiabilidad y el margen de error
Cuando las encuestadoras presentan sus resultados, proporcionan una ficha técnica donde se indica, entre otras cosas, el tamaño de la muestra, la confiabilidad y el margen de error. El primero se elige de acuerdo a la confiabilidad que se desea para el resultado, y al margen de error que se quiere en dar dicho resultado. Mientras más confiabilidad y menos margen de error se deseen, más grande debe ser la muestra. Lógicamente, si esta es del tamaño de la población (censo), la confiabilidad será del 100% y el margen de error, 0%; asumiendo que no se han cometido errores al recopilar, ingresar y procesar los datos.

Cuando se informa, por ejemplo, qué porcentaje de electores votaría por el candidato A, aunque solo se suele indicar el resultado de la encuesta (por ejemplo, el 23%), lo que realmente nos dicen las encuestadoras es que el porcentaje de electores que votaría por el mencionado candidato está en el rango de 23% ± 3%, donde 3% es el margen de error previamente fijado y expresado en la ficha técnica, juntamente con la confiabilidad, que suele ser del 95%. En conclusión, el porcentaje de votantes del candidato está entre 20% y 26%; pero, al ser 95% confiable, existe una probabilidad del 5% de fallar, es decir, de que el verdadero porcentaje de electores que voten por el candidato no esté en el rango de 20% a 26% determinado por la encuestadora.
El empate técnico
Cuando los rangos de los resultados porcentuales de dichos candidatos coinciden parcialmente, se da un empate técnico. En este caso, no se podría afirmar qué candidato tiene mayor porcentaje de votos. Por ejemplo, en los resultados de las encuestas a boca de urna de las últimas elecciones municipales de Piura, Ipsos Perú anunció que Juan José Díaz tenía 21,8% ± 5% y Luis Neyra 19,8% ± 5%. Como se ve, no se sabía quién tenía realmente más votos, y no era correcto afirmar que Díaz ocupaba el primer lugar. Ese mismo día, por la noche, Ipsos Perú anunció los resultados de su conteo rápido de actas de votos ya emitidos, declarando que Luis Neyra tenía 21,2% ± 1% y Juan José Díaz 20,2% ± 1%. Nuevamente se presentaba un empate técnico.
Días después, al cierre del conteo de la ONPE, aún no se sabe quién sería el alcalde de Piura, pues, faltando procesar más de 100 actas por parte del JEE (más de 20 000 votos), Juan José Díaz tenía el 20,45%, y Luis Neyra el 20,20% de los votos. Esta diferencia de 0,25% corresponde a 846 votos.
El tamaño de la muestra
Existe una fórmula (Hasek, 1960) para determinar el tamaño de la muestra, a partir del tamaño de la población, y de la confiabilidad y el margen de error que se fijen. Si se usa para estimar el porcentaje de una población de 15 000 personas que votarán por un candidato X, con un margen de error del 5% y una confiabilidad del 95%, se determina que se necesita una muestra de 375 votantes. Si, en cambio, se desea un margen de error del 2%, la muestra debe ser de 2075 votantes. Como se ve, mientras menor margen de error se desee, más grande debe ser la muestra.
Para poblaciones grandes (más de 50 000 personas), según la fórmula de Hasek, el tamaño de la muestra prácticamente no depende del de la población. Por ejemplo, si se quiere que los resultados porcentuales tengan una confiabilidad del 95% y un margen de error del 2%, habría que encuestar a 2400 personas, tanto para Piura como para una población mucho más grande como la de Lima.
A partir de esta fórmula, para poblaciones grandes, en la figura 1 se muestra cómo el margen de error depende del tamaño de la muestra, para una confiabilidad del 95%. Por ejemplo, para una muestra de 200 votantes, el margen de error es aproximadamente 7%. Con 600 votantes, sería de un 4%, aproximadamente.
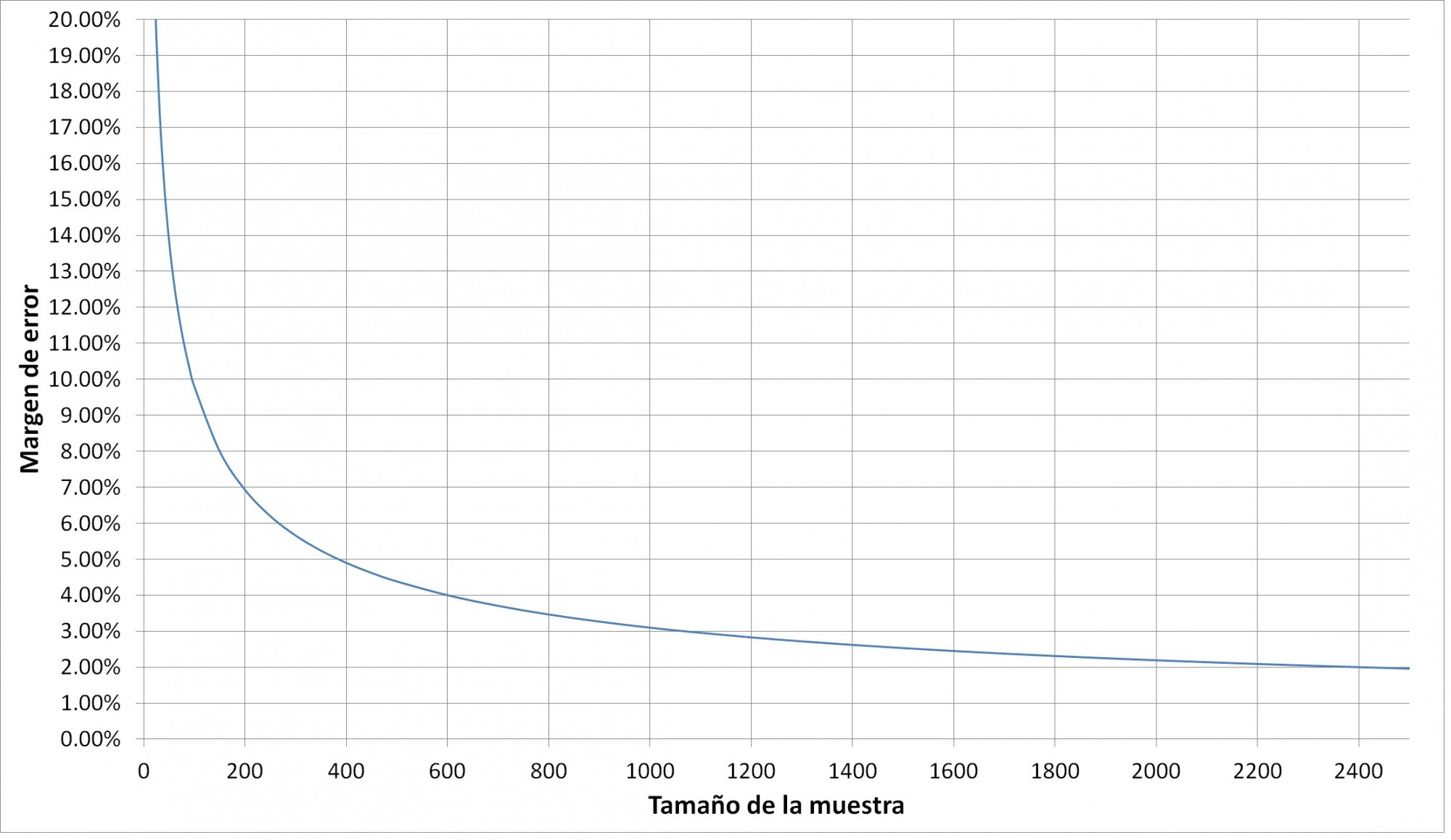
Figura 1.
El margen de error para los resultados por estratos
Es importante tener en cuenta que, si una encuestadora presenta resultados para algunos estratos de la población, en la ficha técnica debería indicar cuál es el margen de error para cada estrato, pues, lógicamente, al tener cada estrato un determinado tamaño de muestra, su margen de error depende de dicho tamaño.

Doctor César Angulo, docente de la Facultad de Ingeniería de la UDEP.
En las elecciones municipales en la provincia de Piura, una encuestadora presentó una ficha técnica indicando que hizo 600 encuestas. Con una confiabilidad del 95%, el margen de error es 4%. Pero, si la encuestadora quisiera presentar resultados porcentuales para cada distrito, los márgenes de error en los más pequeños serían demasiado grandes, pues sus correspondientes muestras son demasiado pequeñas, tal como se aprecia en la tabla de la figura 2, donde se ve la composición porcentual de los diez distritos de la provincia de Piura, los tamaños de sus poblaciones y de las muestras, y sus correspondientes márgenes de error. Como se ve, muchos distritos tendrían márgenes de error elevadísimos.
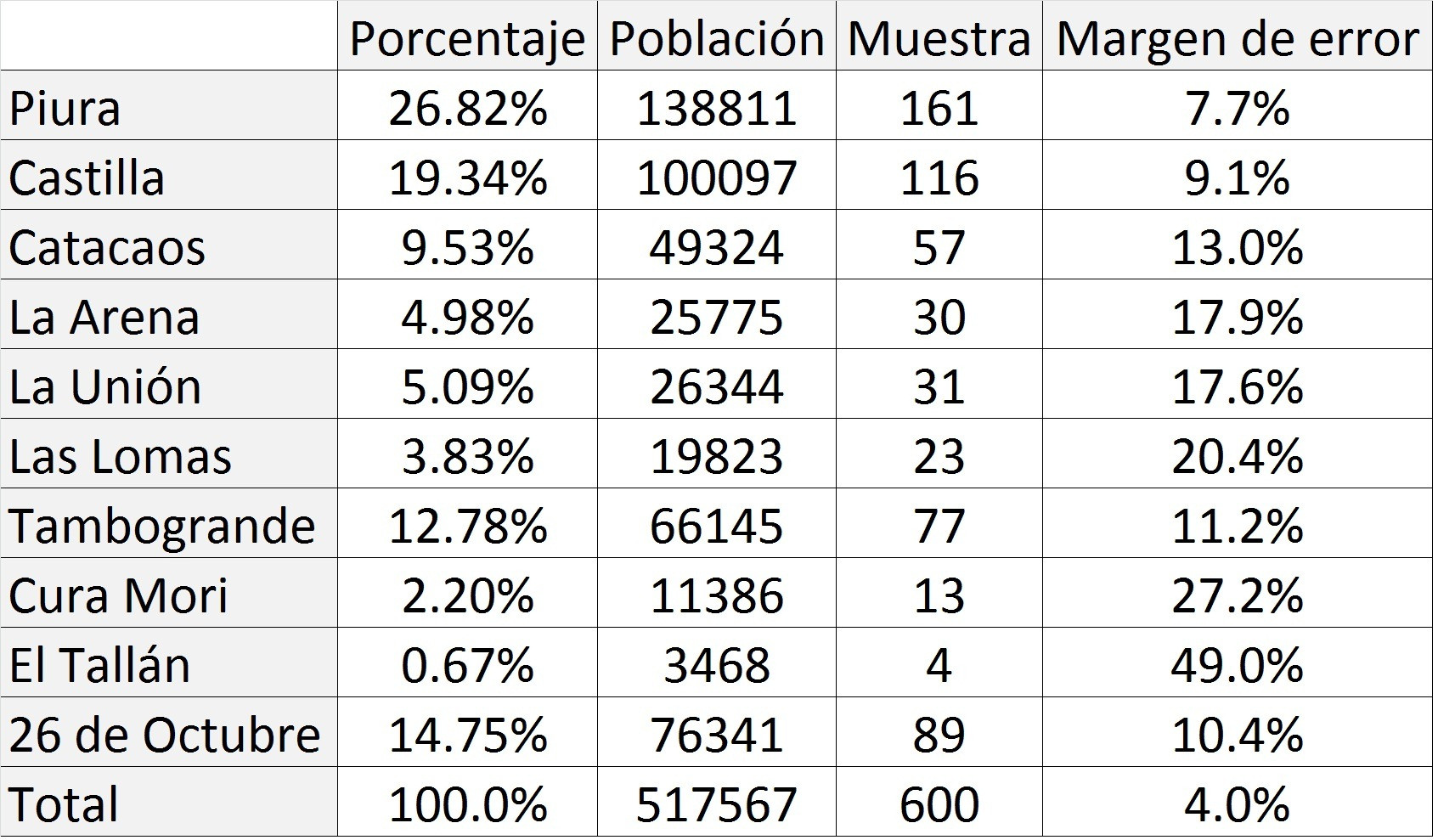
Figura 2.
¿Qué tendría que hacer la encuestadora si desea presentar resultados para cada distrito y no quiere incurrir en márgenes de error tan grandes? La respuesta es evidente: tendría que aumentar el tamaño de las muestras de cada distrito, de tal manera que cada margen de error no resulte tan grande. Para esto, podría considerar a cada distrito como una población independiente y fijar un margen de error para cada uno, por ejemplo, del 5%, y a partir de esto, determinar su correspondiente tamaño de muestra.







